Wednesday, August 30, 2006
Gargoyles and the All-Data Problem

Overly-simplifying assumptions and sweeping generalizations are the kiss of death for effecting change. In the data space, we have universal problems like information overload that are massive in scale. Thus the laissez-faire folks (like Cory Doctorow and Clay Shirky) seem to basically assume that the scope is just too large for any meaningful top-down solution.
Let's take a brief diversion here with an amusing, fictional analogy. In the fictional novel, Snow Crash, by Neal Stephenson there are characters called "Gargoyles" (as I attempted to sketch here) that are derided by the protagonist as goons because they attempt to collect any and all data in their vicinity with the hope something is of value. The derision is chiefly aimed at the brute-force strategy of collecting everything. The protagonist's derision is attacking the lack of discrimination in the method. I call this very lack of discrimination - the "All Data Problem". In fact, I would assert that the laissez-faire camp make this same mistake.
The "All Data Problem" makes a blanket assumption that our solution must be applied to all data and therefore will run headlong into failure due to massive scope. But what must be understood clearly is that the "All-Data Problem" is a flawed argument for one simple reason:
All Data is Not Equal.
Thus, for example, all data does not require metadata... all data does not require formal semantic models ... it is foolhardy to apply web-based principles applicable to the internet as a whole to an organization's data.
All Data is Not Equal.
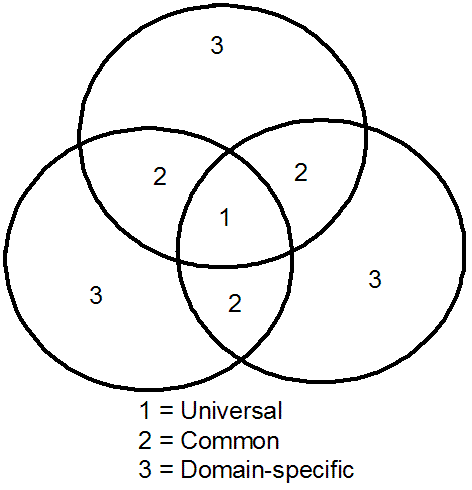
I have a solution to the "All-Data Problem" that I will demonstrate over the next few posts. First, let's examine a precedent... In the National Information Exchange Model, I established the following scoping principle as shown in the diagram on the right. Universal entities were shared among all domains, common entities were shared among two or more domains and domain-specific entities were only used within their domain. Each type of entity required different degrees of harmonization and governance.
All Data is Not Equal...
Comments:
<< Home
Mike,
Information overload is actually an argument for algorithmic approaches to data management and against metadata-heavy approaches. Why? Because the sheer volume of information makes it impractical to tag and/or build explicit models to describe and discover the universe of information available.
Information overload is actually an argument for algorithmic approaches to data management and against metadata-heavy approaches. Why? Because the sheer volume of information makes it impractical to tag and/or build explicit models to describe and discover the universe of information available.
# posted by  : 12:25 PM
: 12:25 PM
: 12:25 PM
I agree with one part of your post and disagree with another part.
As I said in the post, "All data does not require metadata..."
Thus, if you view the "information overload problem" as involving "all data", which is somewhat of a defensible position in our current environment, than you are correct in that an algorithmic approach handles "all data" whereas a metadata approach breaks down due to the effort required.
However, let me state that I do not believe that the solution to "Information Overload" requires an "All-Data" solution. The key to information overload is proper selection. This is the same general solution we apply to sensory overload ... you cannot focus on all input, so you selectively filter out only what is required to do the immediate task. In my opinion, that same solution is the key to information overload. How do we help us filter rapidly. The answer is the selective use of metadata. For example, for some tasks, geographic filtering is critical. Use of metadata to identify geospatial information will quickly enable that information to be plotted on a map. Thus, I see the key to solving information overload as the ability to know which data in your organization (or in your life) should be managed. That answer is not "all data". Once you answer that question, you will apply metadata to that information you need to manage.
Post a Comment
As I said in the post, "All data does not require metadata..."
Thus, if you view the "information overload problem" as involving "all data", which is somewhat of a defensible position in our current environment, than you are correct in that an algorithmic approach handles "all data" whereas a metadata approach breaks down due to the effort required.
However, let me state that I do not believe that the solution to "Information Overload" requires an "All-Data" solution. The key to information overload is proper selection. This is the same general solution we apply to sensory overload ... you cannot focus on all input, so you selectively filter out only what is required to do the immediate task. In my opinion, that same solution is the key to information overload. How do we help us filter rapidly. The answer is the selective use of metadata. For example, for some tasks, geographic filtering is critical. Use of metadata to identify geospatial information will quickly enable that information to be plotted on a map. Thus, I see the key to solving information overload as the ability to know which data in your organization (or in your life) should be managed. That answer is not "all data". Once you answer that question, you will apply metadata to that information you need to manage.

{kind=link}
<< Home