Wednesday, August 30, 2006
Gargoyles and the All-Data Problem

Overly-simplifying assumptions and sweeping generalizations are the kiss of death for effecting change. In the data space, we have universal problems like information overload that are massive in scale. Thus the laissez-faire folks (like Cory Doctorow and Clay Shirky) seem to basically assume that the scope is just too large for any meaningful top-down solution.
{kind=link}
Let's take a brief diversion here with an amusing, fictional analogy. In the fictional novel, Snow Crash, by Neal Stephenson there are characters called "Gargoyles" (as I attempted to sketch here) that are derided by the protagonist as goons because they attempt to collect any and all data in their vicinity with the hope something is of value. The derision is chiefly aimed at the brute-force strategy of collecting everything. The protagonist's derision is attacking the lack of discrimination in the method. I call this very lack of discrimination - the "All Data Problem". In fact, I would assert that the laissez-faire camp make this same mistake.
The "All Data Problem" makes a blanket assumption that our solution must be applied to all data and therefore will run headlong into failure due to massive scope. But what must be understood clearly is that the "All-Data Problem" is a flawed argument for one simple reason:
All Data is Not Equal.
Thus, for example, all data does not require metadata... all data does not require formal semantic models ... it is foolhardy to apply web-based principles applicable to the internet as a whole to an organization's data.
All Data is Not Equal.
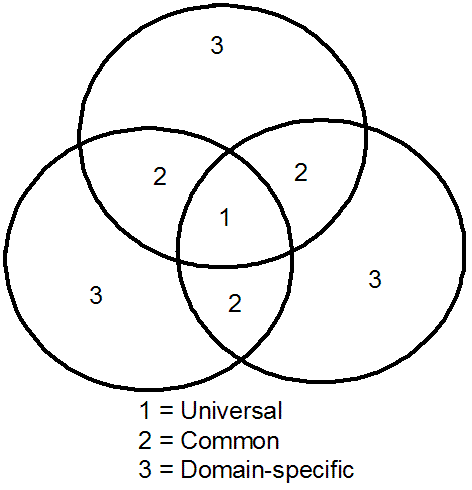
I have a solution to the "All-Data Problem" that I will demonstrate over the next few posts. First, let's examine a precedent... In the National Information Exchange Model, I established the following scoping principle as shown in the diagram on the right. Universal entities were shared among all domains, common entities were shared among two or more domains and domain-specific entities were only used within their domain. Each type of entity required different degrees of harmonization and governance.
All Data is Not Equal...
Friday, August 25, 2006
Semantic Metadata Management and SOA Metadata
Several interesting acquisitions have occured in the intersection of the metadata registry and SOA spaces. BEA acquired flashline and WebMethods acquired Cerebra. Having known Jeff Pollock for a few years, I am glad to see a semantic web company seen as a valuable commodity. Jeff is a fellow John Wiley author who co-authored the book (which I recommend as a good read) entitled Adaptive Information.
What does this mean? Primarily two things - first, it is a good example of Combinatorial experimentation which I discuss in my Semantic Web book as a brute-force approach to experimentation (fueled by the internet) where we continually combine things to search for the right combination which leads to productivity leaps.
Of course, I am not saying that combinatorial experimentation is the first or only reason why these acquisitions were made ... BEA and WebMethods are better businesses than that. However, you create new combinations when the current approach is not as effective as it should be.
Thus, the realization that semantics and metadata are critical to implementing the SOA vision.
What does this mean? Primarily two things - first, it is a good example of Combinatorial experimentation which I discuss in my Semantic Web book as a brute-force approach to experimentation (fueled by the internet) where we continually combine things to search for the right combination which leads to productivity leaps.
Of course, I am not saying that combinatorial experimentation is the first or only reason why these acquisitions were made ... BEA and WebMethods are better businesses than that. However, you create new combinations when the current approach is not as effective as it should be.
Thus, the realization that semantics and metadata are critical to implementing the SOA vision.
Saturday, August 19, 2006
Metadata design
Currently working on a demonstration of the principles of metadata design. I am considering a resource type of which to use as an example. Please comment if you have suggestions. I want to use something that has not been done many times over (like music). My current thinking is to do metadata design on desktop applications. One ramification of this would be a requirement to change the definition of metadata from just a description of data to a description of an electronic resource (as clearly both applications and services would not be considered data).
Your thoughts and suggestions are welcome...
Your thoughts and suggestions are welcome...
![]()